🎈前言
一直都挺好奇广义线性模型(Generalized Linear Model)是怎么跑起来的。以前经常遇到这个东西,不过之前用的时候一直都在当纯粹的调包侠,没有去纠结它的原理。最近又突然想起来这个东西就在空闲时间看了一下…就…虽然和现在的前端工作也没什么关系就是了。
广义线性模型由 Nelder 和 Wed derburn 在 1972 年提出,详见 Generalized Linear Models。简单来说,广义线性模型就是使用连接函数(Link Function),使得可以是非连续、非正态的因变量可以表示为自变量的线性组合。对于线性回归模型,假设变量连续、正态。对于因变量离散、非正态的情况,线性回归模型的假设就得不到满足。而广义线性模型仅要求因变量的分布属于指数分布族(Exponential Family),对因变量没有任何的限制。
这篇博客主要是 Annette J. Dobson 的 《AN INTRODUCTION TO GENERALIZED LINEAR MODELS SECOND EDITION》的学习笔记。
🧵指数分布族
指数分布族是仅依赖一个参数 θ,概率分布形式如下的分布:
f(y;θ)=exp(a(y)b(θ)+c(θ)+d(y))
当 a(y) 是恒等函数时,称为自然形式(Canonical Form):
f(y;θ)=exp(yb(θ)+c(θ)+d(y))
不难发现,正态分布、二项分布、泊松分布等很多常见的分布都属于指数分布族:
| 分布 |
密度函数 |
指数分布族的样子 |
| 正态 |
2πσ1exp(−2σ2(y−μ)2) |
exp(σ2μy−2σ2μ2−21log(2πσ2)−2σ2y2) |
| 泊松 |
k!λke−λ |
exp(ylogθ−θ−logy!) |
| 分布 |
质量函数 |
指数分布族的样子 |
| 二项 |
(πn)πk(1−π)n−k |
exp(ylog1−ππ+nlog(1−π)+log(yn)) |
假设 Y 服从指数分布族,
∫−∞+∞f(y;θ)dy=1
如果 f 和 ∂θ∂f 在 (−∞,+∞)×[m,n] 一致连续,
dθd∫f(y;θ)dy=∫∂θ∂f(y;θ)dy=0∫f(y;θ)(a(y)b′(θ)+c′(θ))dy=0
于是就有
∫f(y;θ)a(y)dy=E(a(Y))=−b′(θ)c′(θ)(1)
接下来求方差 Var(a(Y)),如果 ∂θ2∂2f 存在,类似地,
∂θ2∂2f(y;θ)=((a(y)b′′(θ))+c′′(θ))f(y;θ)+(a(y)b′(θ)+c′(θ))2f(y;θ)
由(1),右侧第二项可以写成
(b′(θ))2⋅(a(y)−E(a(Y)))2f(y;θ)
由于 ∫(a(y)−E(a(Y)))2f(y;θ)dy=Var(a(Y)),∫f(y;θ)dy=1
∫∂θ2∂2f(y;θ)dy=b′′(θ)E(a(Y))+c′′(θ)+(b′(θ))2Var(a(Y))=0
于是,
Var(a(Y))=(b′(θ))3b′′(θ)c′(θ)−c′′(θ)b′(θ)(2)
🧶广义线性模型
广义线性模型要求因变量 Y1,Y2,⋯YN 是独立随机变量,服从同一个自然形式的指数分布族的分布,它们的参数 θi 不一定相同。模型假设 g(E(Yi)) 可以由 p(p<N)个自变量 xij 的线性组合表示,g 是连接函数:
E(Yi)=μig(μi)=xiTβxiT=(xi1,xi2,⋯,xip)β=(β1,β,⋯,βp)T
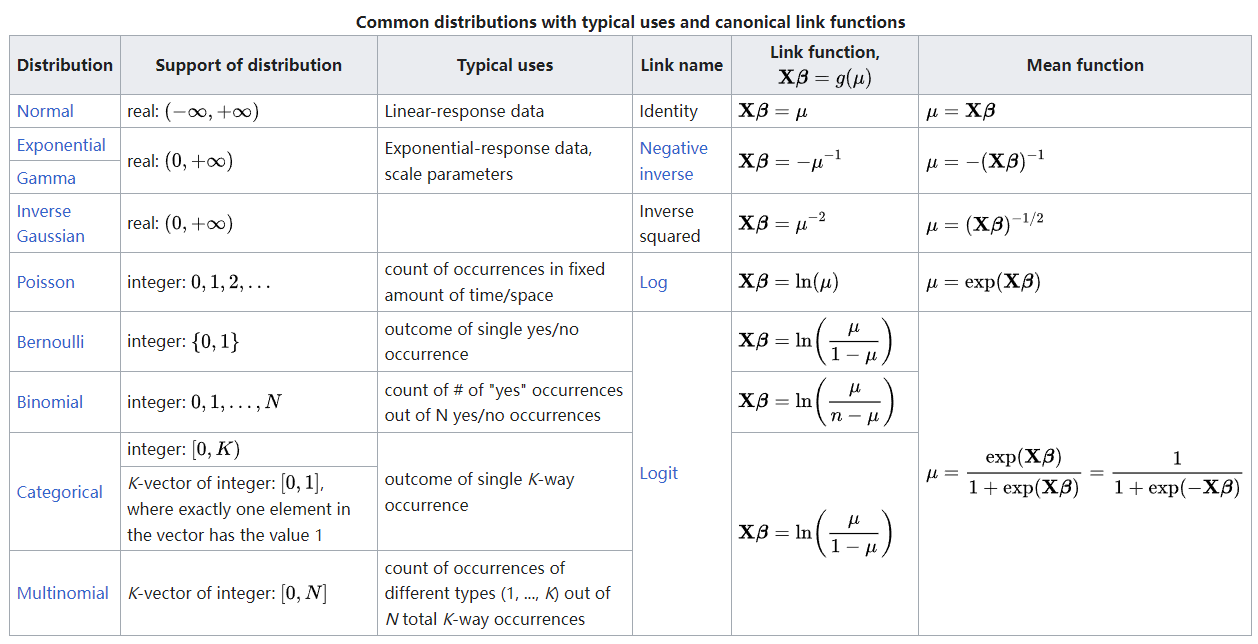
关于连接函数的选择,似乎一下子没有搜到什么资料,下面是维基百科的一个常见连接函数表格:
🔮最大似然估计
参数求解使用最大似然估计进行,对于每个 Yi 有对数似然函数:
li=yib(θi)+c(θ)+d(yi)
加起来就是
l=i=1∑Nli=∑yib(θi)+∑c(θ)+∑d(yi)
由于难以获得解析解,这里使用牛顿法进行数值求解,迭代过程用 bk 表示 β。
bk+1=bk−(∇2l)−1∇l
∇lj=Uj=∂βj∂(∑yib(θi)+∑c(θ)+∑d(yi))=i=1∑N∂θi∂li∂μi∂θi∂βj∂μi
根据(1):
∂θi∂li=yib′(θi)+c′(θi)=b′(θi)(yi−μi)
再根据(1)和(2):
∂μi∂θi=1/∂θi∂μi∂θi∂μi=(b′(θi))2b′′(θi)c′(θi)−c′′(θi)b′(θi)=b′(θi)Var(Yi)
由 g(μi)=xiTβ
∂βj∂μi=∂g(μi)∂μi∂βj∂g(μi)=∂g(μi)∂μixij
因此
Uj=i=1∑NVar(Yi)yi−μixij∂g(μi)∂μi
记黑塞矩阵 J=∇2l,一般我们都取它的期望值 E(J),这里不直接计算 J,我们使用费舍尔信息矩阵(Fiesh Infomation Matric),它是一阶梯度协方差矩阵的期望,可以证明它是黑塞矩阵期望的负值,见这里。
−Jjk=E(UjUk)=E(i=1∑NVar(Yi)yi−μixij∂g(μi)∂μi⋅l=1∑NVar(Yl)yl−μlxlk∂g(μl)∂μl)
由 Yi 相互独立,E((Yi−μi)(Yl−μl))=0,i=l
−Jjk=i=1∑N(Var(Yi))2E((Yi−μi)2)xijxik(∂g(μi)∂μi)2=i=1∑N(Var(Yi))2Var(Yi)xijxik(∂g(μi)∂μi)2=i=1∑NVar(Yi)xijxik(∂g(μi)∂μi)2
因此
bk+1=bk+(E(J))−1U
🔍模型检验
模型检验一般考虑对数似然(比)统计量(Log Likelihood (Ratio) Statistic)。用 D,即 Deviance 表示。
D=2(l(bmax;y)−l(b;y))
l 是对数似然函数。bmax 是全模型的估计的参数,全模型的参数数量在各个模型中是最多的。b 是你所感兴趣的模型的参数估计。D 服从非中心的卡方分布,
D∼X(m−p,v)
m、p 分别是全模型、所感兴趣的模型的参数数量,v=2(l(bmax;y)−l(b;y)) 如果所感兴趣的模型拟合得全模型差不多好,v 接近于 0。
对于相同连接函数和分布的两个广义线性模型,
H0:β=β0=(β1,⋯,βq)H1:β=β1=(β1,⋯,βp)q<p
考虑统计量
ΔD=D0−D1=2(l(b1;y)−l(b0;y))
如果两个模型拟合效果相近,有 ΔD∼X(p−q),当 ΔD 大于 X(p−q) 的 α,拒绝零假设。
?结语
这篇博客稍微简单地回顾了一下广义线性模型的计算方法和模型验证。